![]()

Google擁有許多種生成模型,當我們輸入關鍵字時,Google會選擇其中一種、多種,或者「不使用」生成模型來回應我們。
不使用生成模型(未顯示SGE)
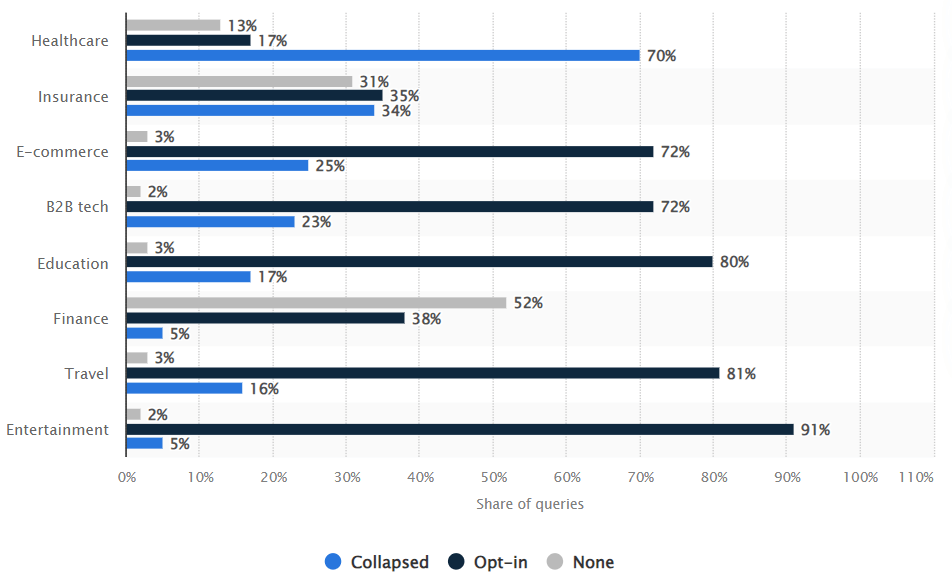
如果沒有顯示 SGE,可能是 Google 不使用生成模型生成回應的結果。而根據 statista 的統計,SGE在金融、健康等領域較少出現,也就是所謂的「YMYL」關鍵字(Your Money or Your Life)。
為什麼Google在某些領域,尤其是「YMYL」中不使用生成模型呢?
我猜是因為SGE目前爭議還很多,加上在美國,一個普通人告贏大公司的案例並不少見,要是SGE的回答出了什麼狀況(像是「Yessssssss. It’s generally recommended to drink while on antibiotics. Yippe!!!!!!!!!!!!!!!!!!!!!!」這種怪回答),就很容易被抓到小辮子。
選擇一種、多種生成模型(顯示SGE)
當搜尋結果中顯示 SGE 時,表示 Google 選擇了一種或多種生成模型來生成回應。
什麼時候只用一種,什麼時候用多種,又有幾種生成模型,目前還不太確定。但以下是已知的兩種生成模型:
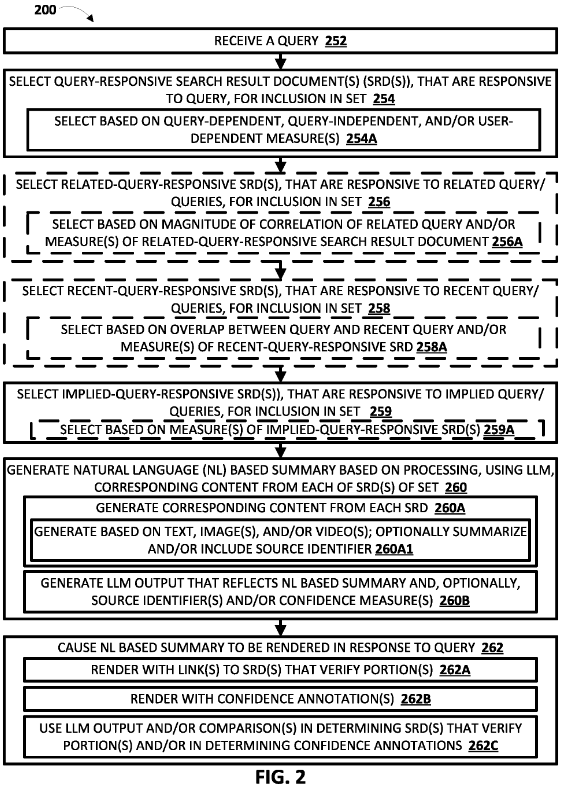
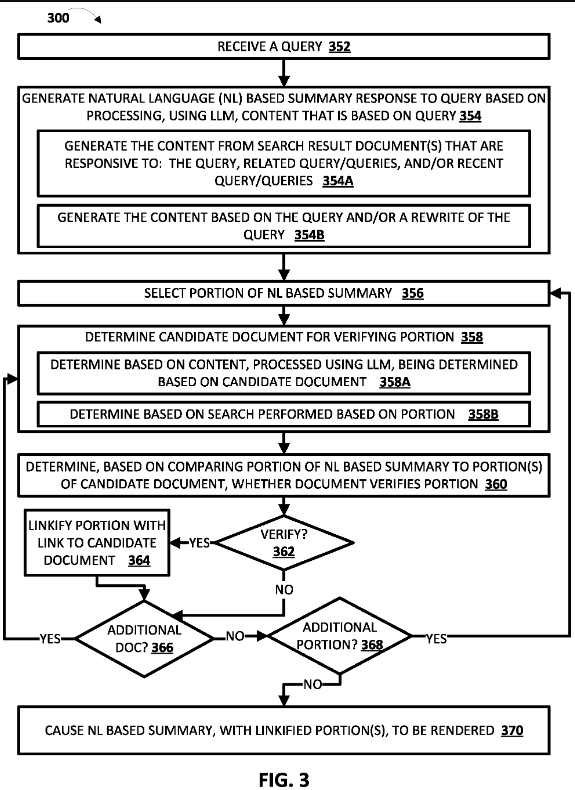
生成模型 200:先撈文本,再生成回答
200 的運作原理是當使用者搜尋關鍵字時,Google 會先用某種演算法(可能是 EEAT、DR、相關性、地區)篩選出幾個文本,然後用大型語言模型 ( LLM )處理並生成回應,最後再附上參考文本的連結。
用「防曬乳怎麼用」的舉例就是:
- 使用者查詢「防曬乳怎麼用」
- Google 選擇「生成模型 200」來生成回應
- Google 先使用某種演算法選擇了 A、B、C 三篇文章
- Google 將 A、B、C 丟給大型語言模型 (LLM)處理
- LLM 重組三篇文章,並生成一段流暢的回答
- SGE 顯示回答,並且附上 A、B、C 三篇文章的連結
生成模型 300:先生成回答,再用文本驗證
300 的原理是 Google 可能有事先訓練過大量的文本,因此當使用者搜尋關鍵字時,大型語言模型 ( LLM ) 可以直接先生成回答,再用文本去驗證生成的回答是否正確,正確的話再提供用來驗證文本的連結。
用「防曬乳怎麼用」的舉例就是:
- 使用者查詢「防曬乳怎麼用」
- Google 選擇「生成模型 300」來生成回應
- LLM 生成一段流暢的回答
- 為了驗證生成回答的第一段是否正確,Google 利用某種演算法找了 A 文章來驗證。
- 如果驗證後正確,驗證生成回答第二段
- 如果驗證後錯誤,找其他文章驗證
- 第一段驗證完畢後,需驗證生成回答的第二段是否正確,因此 Google 利用某種演算法找了 B 文章來驗證。
- 如果驗證後正確,驗證生成回答第三段
- 如果驗證後錯誤,找其他文章驗證
- 持續驗證,直到生成回答的每個段落都驗證完畢
- SGE 顯示回答,並且附上所有驗證文本的連結
Google 如何優化 SGE 生成結果?
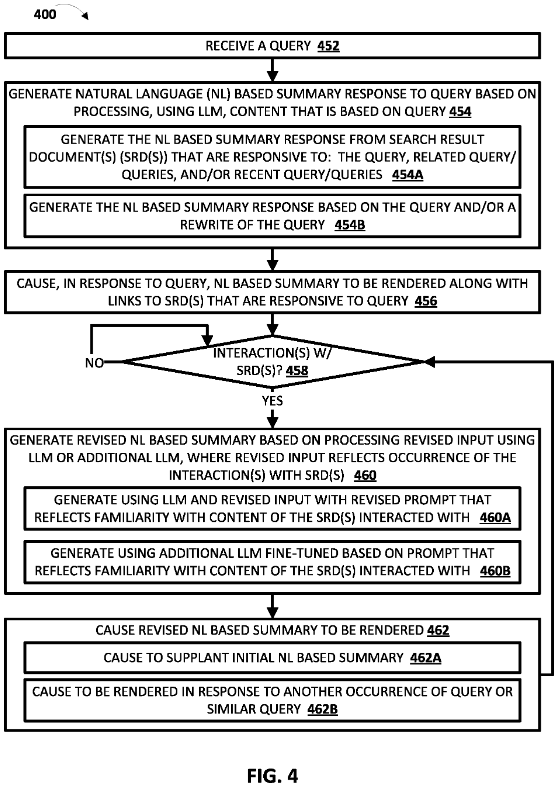
當 SGE 顯示後,Google 會根據使用者與SGE的互動來優化結果,互動越高,可能代表使用者對 SGE 生成的內容不滿意。
下次處理相同或相似的關鍵字時,SGE 會不斷調整說法,直到使用者滿意,也就是不再與 SGE 互動為止。
Key Takeaways
SGE 引用文章看起來是隨機的,但有 2 個面向是我們可以去優化的:
演算法面
不管是 200 還是 300,Google 都會利用演算法選擇文本。因此,掌握這個「演算法」在乎的「Ranking Factor」就很重要,雖然目前沒有這個演算法的相關資訊,但重要的點無非就「DR」、「關聯性」、「地區性」等等。
內容面
當內容夠全面、夠完整、夠有深度、能寫出目前網路上不存在的「乾貨」,那 SGE 在引用文本時,也就只能引用你的內容。因此我認為即使 SGE 正式開放,網站的內容也還是 SEO 中最重要的部分。